A relative URL is any URL that doesn’t explicitly specify the protocol (e.g., ” http:// ” or ” https:// “) and/or domain ( www.example.com ), which forces the visitor’s web browser (or the search engine bots) to assume it refers to the same site on which the URL appears.
Relative Link
A relative link, on the other hand, takes advantage of the fact that the server knows where the current document is. Thus, if we want to link to another document in the same directory, we don’t need to write out the full URL. All we need to use is the name of the file.
Relative Path vs Absolute Path:
Absolute paths contain a complete URL, which includes a protocol, the website’s domain name, and possibly a specific file, subfolder, or page name. For example A Folder
The URL here, http://domain.com/ourfolder, can be entered into a browser’s search bar, and we’ll be taken where we want to go. While our personal browser may let us omit the protocol, https://, we should always include the protocol when coding absolute links to make sure they work for all visitors.
Conversely, a relative link only includes the name of a specific file or page, which is relative, to the current path. If we keep all of our website’s files in a single directory, we can establish links between pages as follows:
The Homepage of my website
Relative URLs come in three flavors:
1. Path-Relative URLs
<a href=”services/video-production/corporate-videos”>
<a href=”corporate-videos”>
The URL begins with the name of a page, or the name of a path (folder, directory, whatever) containing a page. Browsers assume this link refers to a page that is either in the same directory as the page on which the link appears, or in a subdirectory below it.
For example, let’s say a site has a Services section, and under that have a subsection called Video Production, and that the overview page for this service has the URL:
http://example.com/services/video-production
<a href=”video-production”>
Having no domain or foreslashes, this link is assumed by browsers to be relative to the path of the page on which it appears, correctly calculating the absolute URL for this link as:
“http://example.com/services/video-production/”
This is a perfectly valid use for path-relative URLs.
2. Root-Relative URLs
Examples:
<a href=”/services/”>
<a href=”/services/video-production”>
The leading foreslash before “services” indicates that this URL is relative to the root of the site’s URL structure, rather than the path of the page on which it appears. In this case, the absolute URL is calculated to be:
“http://example.com”
“http://example.com”
+ “/services/video-production
Root-relative URLs are probably the safest kind of relative URL overall, both for minimizing the potential for human error, and for simplifying site maintenance. When absolute URLs aren’t an option, root-relative URLs are probably best.
3. Protocol-Relative URLs
Examples:
<a href=”//services/”>
<a href=”//services/video-production”>
The double-leading-foreslash (“//”) tells the browser to use the same connection scheme or protocol (i.e., either HTTP or HTTPS) as used to request the page on which the URL appears, so if this URL is on a page whose URL begins “https://”, then protocol-relative URLs on that page should also begin with “https://”.
Screenshot before applying snippets of code:
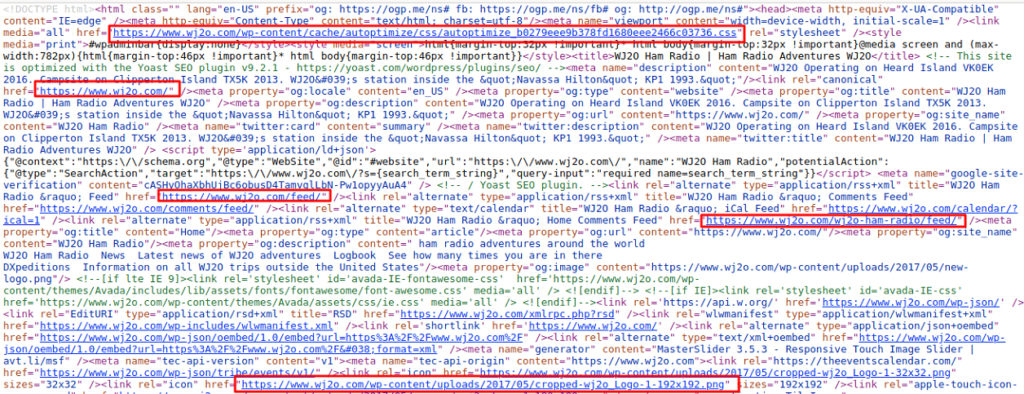
Screenshot after applying snippets of code:
